DTW distance can be aligned to different times [1].
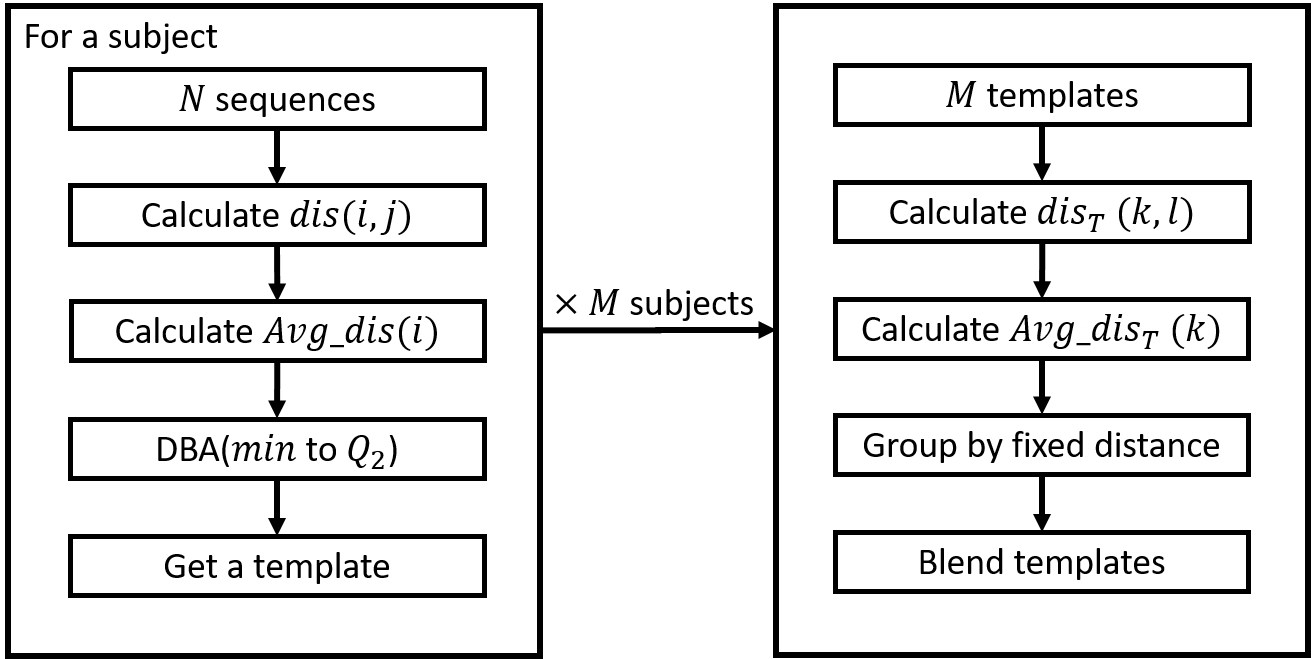
Flowchart for generating blending templates for each activity.
[利用動態時間校正混合模板進行動作辨識]
ABSTRACT:
Activity recognition is a popular research topic. Traditionally, it is mainly based on image input. However, image-based devices are expensive and not easy to carry, and have occlusion problem. On the contrary, wearable devices are lightweighted and easy to carry. Consequently, action recognition research has changed from taking image input to taking sensor data input. Wearable devices usually include accelerometers and gyroscopes. We can speculate wearer’s movements with the data. Our action recognition uses dataset of wearable devices. Sequence matching is a common recognition method. In it, Dynamic Time Warping (DTW) is the most widely used one. DTW usually applies to speech recognition. It also has been applied to wearable device recognition in recent years. DTW needs to select a representative sequence as the template, and compare the target sequence with the template sequence. Therefore, the quality of the template will affect the recognition rate, and how to choose the template will be a challenge. This paper proposes an effective feature combination according to activity recognition based on dynamic time warping using wearable devices. This combination is suitable for recognizing individual activities. This paper also proposes a set of processes to blend universal templates. Best individual templates of all subjects are grouped by fixed distance then each group is blended into a template. The accuracy of blending templates is higher than that of the single template, and the recognition time of blending templates is less than that of the multiple templates.
SUMMARY (中文總結):
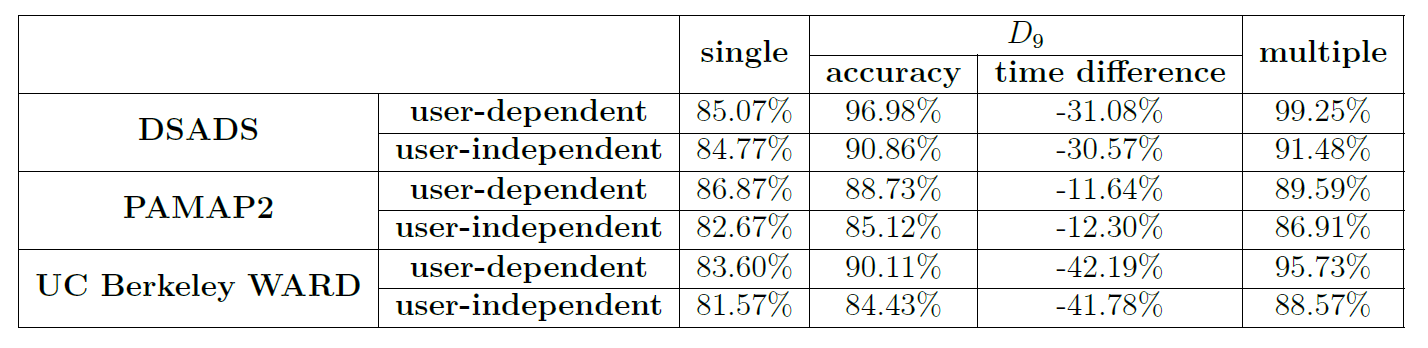
本篇論文中,主要在探討基於DTW的動作辨識,主要提出了兩個貢獻。首先根據三個數據集(DSADS [2]、PAMAP2 [3]及UC Berkeley WARD [4])的實驗結果,我們提出了一組有效的特徵組合,即加速度、角速度與角度,此特徵組合能在基於DTW的辨識中,有效的辨識個人的動作。而序列比對(sequence matching)的辨識,除了改進演算法外,模板也是影響比對時間與準確度的因素。因此我們也提出了適合DTW動作辨識的混和模板。當所有受測者的個人最佳模板以固定距離\(D_9\)去做分群並將每群混和出模板後,此時的模板有不錯的結果。此時混合模板的準確度能高於單模板的準確度,比對時間能少於多模板。而混合模板是適用於所有受測者的user-independent模板,但限制在於需要所有受測者對每種活動有相同的解釋與風格下。
RESULTS:
Results of three datasets with single template and multiple templates at fixed distance \(D_9\).
Comparison of our method with CNN in three datasets.

REFERENCES:
[1] Thanawin Rakthanmanon, Bilson Campana, Abdullah Mueen, Gustavo Batista, Brandon Westover, Qiang Zhu, Jesin Zakaria, and Eamonn Keogh. Addressing big data time series: Mining trillions of time series subsequences under dynamic time warping. ACM Transactions on Knowledge Discovery from Data (TKDD), 7(3):1–31, 2013.
[2] Kerem Altun, Billur Barshan, and Orkun Tuncel. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognition, 43(10):3605–3620, 2010.
[3] Attila Reiss and Didier Stricker. Introducing a new benchmarked dataset for activity monitoring. 2012 IEEE 16th International Symposium on Wearable Computers, pages 108–109, 2012.
[4] Allen Y Yang, Roozbeh Jafari, S Shankar Sastry, and Ruzena Bajcsy. Distributed recognition of human actions using wearable motion sensor networks. Journal of Ambient Intelligence and Smart Environments, 1(2):103–115, 2009.