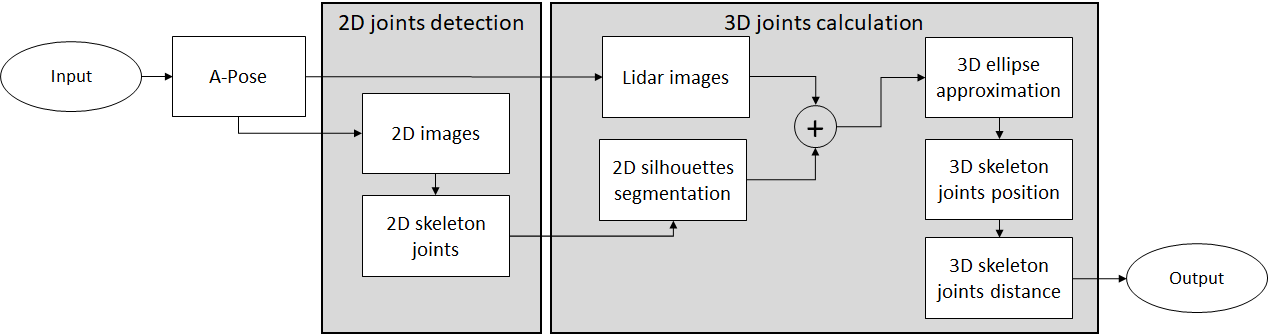
Flowchart of our system.
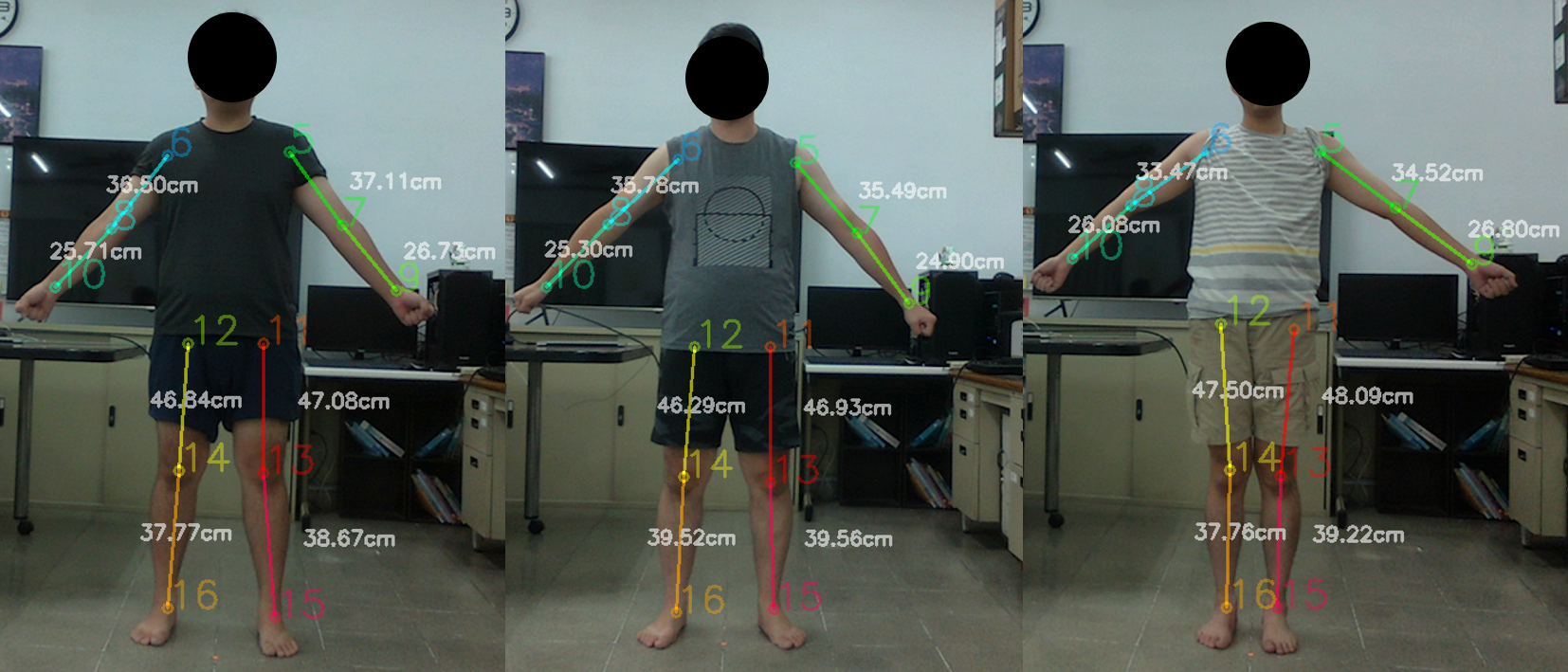
Results of our system.
[基於光學雷達技術的3D骨架測量]
Motion capture technology was originally designed to simplify the process of animation production by eliminating the time-consuming and laborious task of drawing character animation frame by frame. In prior years, motion capture technology requires expensive equipment, that could only be afforded by the film industry. Furthermore, the collected data is frequently inaccurate, which needs to be manually fine-tuned in the post-production stage. However, thanks to recent advances, motion capture devices gradually become more reliable, and affordable for other applications such as entertainment, logistics and sport training. The vast majority of motion capture systems require the user to measure bone lengths before capturing the motion, except in some rare cases. As a result, the measurement of skeletal length is a crucial step in motion tracking, as it affects the overall accuracy of motion capturing. The most intuitive and obvious way is to measure the bone length is with a ruler. However, this conventional process is an unstable factor in the overall quality of motion tracking, since there is a discrepancy between the bone length measured on the skin surface and the actual bone length. In addition, the measuring process costs extra time and labor, both of which can be reduced by automation. This research aims to propose a fast, effortless and robust system to measure the skeletal lengths of the human body, using a single LiDAR camera. Our main goal is to provide an affordable yet reliable device that can be used in medical rehabilitation and other related applications. In order to achieve our objectives, we adopted multiple neural network architectures, including HigherHRNet and DeepLab v3, and an ellipse approximation method based on arc-support vectors. Our experimental result shows that our method has an average error of 3% compared to bone lengths measured by X-ray, which is more accurate than the conventional ruler method.
SUMMARY (中文總結):
骨架測量是動作捕捉系統的前處理流程,通常最直覺的方式是透過手動測量來獲得。但手動測量往往需要額外的人力來為受測者逐節測量其身體各部位的骨頭,不僅費時,也可能因為測量者的背景知識或標準不同,得到的測量結果也因此不同。又因為在皮膚表層測得的長度並非位於肌肉內部的實際骨頭長度,因此手動測量出來的結果可能不是最接近實際骨骼長度的值。
因此我們提出了一個基於2D骨架偵測結合LIDAR深度相機的方法進行實際骨骼長度估計測量。並且使用骨骼X光照片作為我們測量比較時的ground truth。
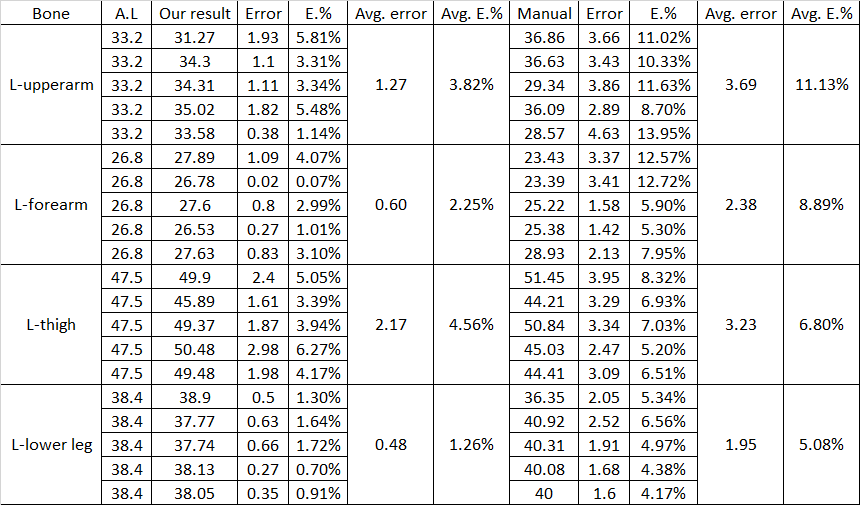
從實驗結果表明,我們提出的方法測得的長度,比起手動測量5次的結果平均,更接近骨骼X光的值。並且針對同一位受測者,我們的方法可以在平均10秒內求出包含四肢在內的結果。但手動測量每一位受測者的目標骨骼(即前臂、上臂、大腿、小腿等8段骨骼),逐節完整測量完需花費平均超過120秒,因此我們提出的方法不僅在測量值比起手動測量更接近骨骼X光照,在測量時間上也比起手動測量花費更少的時間,我們的方法可以取代手動測量作為動作捕捉系統的前處理流程。
RESULTS:
Compare our method with X-ray photos and manual measurement.

REFERENCES:
[1] Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S Huang, and Lei Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5386–5395, 2020.
[2] Changsheng Lu, Siyu Xia, Ming Shao, and Yun Fu. Arc-support line segments revisited: An efficient high-quality ellipse detection. IEEE Transactions on Image Processing, 29:768–781, 2019.
[3] Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3):302–321, 2019.